
Xiaomi at the Trillion-Parameter Table: What MiMo-V2.5-Pro Actually Brings to the Open Frontier
The Quiet Crowding of the Open Frontier

Two years ago, the phrase “trillion-parameter language model” still carried a kind of mythic weight. It evoked closed labs, strategic moats, and whatever GPT-4 was hiding under the hood. The number itself was the message: a trillion parameters meant we are the lab you cannot reproduce. Today, that phrase has lost most of its mystique. Open-weight, MIT- or Apache-licensed mixture-of-experts models in the trillion-parameter range have become a small but real category — released in clusters, downloaded by the terabyte, and benchmarked against each other every other week.

Into that crowded room, the Xiaomi MiMo team has dropped MiMo-V2.5-Pro: a 1.02-trillion-parameter MoE released on Hugging Face under an MIT license, trained in FP8 across 27 trillion tokens, and shipped with a 1-million-token context window. It is the first time a Chinese consumer-electronics company has put a frontier-scale foundation model on the open-weights table with that much technical ambition behind it. And it raises a question that the open-AI conversation has so far been awkward about answering: when several labs have a trillion parameters of their own, what does any individual one of them actually contribute?
What MiMo-V2.5-Pro Is on Paper
The model card reads like a careful synthesis of recent MoE craft. The architecture has 70 layers — 1 dense and 69 mixture-of-experts — with 384 routed experts in each MoE block and 8 experts activated per token. That gives a total parameter count of 1.02 T and an active parameter count of 42 B per token, slightly above Kimi K2’s 32 B and DeepSeek-V3.1’s 37 B. The hidden size is 6144, attention is grouped-query with 128 heads and 8 key-value heads, and the head dimensions are split asymmetrically (192 for query/key, 128 for value).
Three architectural choices stand out. First, attention is hybrid: 60 of the 70 layers use a 128-token sliding-window attention and only 10 are full-global, in a 6:1 ratio. Combined with a learnable attention-sink bias, this trims the key-value cache by roughly seven-fold compared with a fully global trillion-scale model — and it is what makes the 1-million-token context length practical rather than theoretical. Second, the model is trained with Multi-Token Prediction: three lightweight prediction heads run in parallel during inference, claimed to roughly triple decoding throughput, with multi-layer EAGLE-style speculative decoding bolted on top. Third, the entire stack is trained and released in FP8 (E4M3 mixed precision), which means a single 8×80 GB H100 node can serve the model with reasonable headroom.
The post-training pipeline has three stages: ordinary supervised fine-tuning, then domain-specialized reinforcement learning runs for math, safety, and agentic tool use, and finally a “Multi-Teacher On-Policy Distillation” pass that fuses the specialized variants back into one model under token-level guidance from each specialist teacher. There is no explicit reasoning-style RL like the chain-of-thought-rewarded process the DeepSeek-R1 family used. MiMo-V2.5-Pro is, in this sense, a deliberately non-thinking-mode model — single-pass, fast, optimized for throughput rather than for the long internal reasoning budgets that R1 and its imitators trade compute for.
Two checkpoints are released: MiMo-V2.5-Pro itself, the post-trained version with 1 M context, and MiMo-V2.5-Pro-Base, the pre-training-only checkpoint with 256 K context. Both are MIT-licensed and ship via Safetensors with first-class SGLang and vLLM support.
How It Lines Up Against Its Peers
The 2026 open-weight trillion-parameter shortlist is short enough to enumerate. Moonshot’s Kimi K2, released in July 2025 under a modified MIT license, sits at one trillion total parameters with thirty-two billion active per token and a context window of 128 K — almost exactly MiMo’s twin in size, slightly leaner in inference cost. DeepSeek-V3.1, in its December 2024 release with the August 2025 update, weighs 671 billion total and 37 billion active, also under MIT, also at 128 K context. Alibaba’s Qwen3-Coder-480B-A35B is a deliberate sub-trillion coding specialist at 480 billion total and 35 billion active, Apache-2.0-licensed, with a 256 K native context that stretches to a million via YaRN.
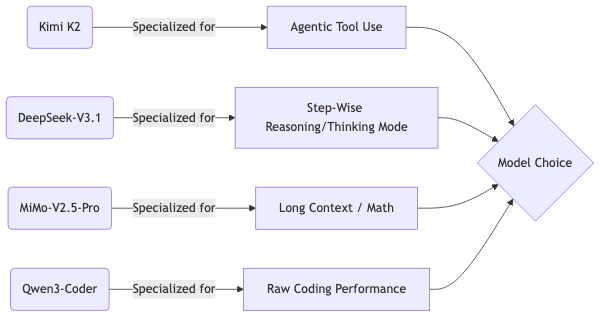
Kimi K2 and MiMo-V2.5-Pro are essentially the same scale. DeepSeek-V3.1 is two-thirds the total parameter count but covers similar territory with a smaller active path. Qwen3-Coder is a coding specialist at sub-trillion scale. Each chooses a different set of trade-offs: Kimi K2 prizes agentic tool use, DeepSeek-V3.1 prizes step-by-step reasoning via its toggleable thinking mode, Qwen3-Coder prizes raw coding performance per dollar, and MiMo-V2.5-Pro prizes long context and inference-time efficiency.
The spec sheets converge on one thing: total parameters are no longer the headline. Every one of these models is a sparse mixture, and the active path is what users actually pay for in latency and cost. The differences lie in what each lab spent its training compute and post-training rounds on.
The Coding Question
For practitioners, the most honest single question is: when I ask one of these models to write or debug code, how good is it actually? On that axis MiMo-V2.5-Pro is the most surprising entry on the list — surprising because it is not the leader.
On LiveCodeBench v6, the most-cited contemporary coding benchmark, the numbers from each model’s own card or technical report tell a clear story. MiMo-V2.5-Pro reports a Pass@1 score of 39.6 in single-shot mode. Kimi K2 reports 53.7 on the same benchmark. DeepSeek-V3.1 reports 56.4 in its non-thinking mode and a much larger 74.8 once its thinking mode is engaged. The difference between MiMo and the leaders, in other words, is not a small one — it is a fifteen- to thirty-five-point gap on a benchmark designed precisely to separate the frontier from the merely capable.
On SWE-Bench, the agentic software-engineering benchmark, the gap is even more pronounced. MiMo-V2.5-Pro reports 35.7 in the AgentLess setting, where the model has no scaffolding to pull files, run tests, or revise patches. Kimi K2 reports 65.8 in the single-attempt agentic setting and 71.6 with multi-attempt sampling — nearly twice MiMo’s score, although under a more permissive evaluation. DeepSeek-V3.1 reports 66.0 in agentic mode. Qwen3-Coder-480B-A35B reports 38.7 on the harder SWE-Bench Pro variant, and is the only sub-trillion model in the comparison: a useful reminder that for coding specifically, the most parameter-efficient model in the room can still beat the largest.
The verdict is uncomfortable for the simplest “bigger is better” reading. MiMo-V2.5-Pro, the largest model in the comparison, is also the weakest on day-to-day competitive coding. HumanEval+ at 75.6 and MBPP+ at 74.1 are perfectly respectable scores, but those are the benchmarks the field has been saturating for two years; they no longer separate the front from the middle of the pack.
There are caveats worth stating plainly. MiMo-V2.5-Pro reports the harder AgentLess SWE-Bench setting, where the model has no agentic scaffolding to pull files, run tests, and revise. DeepSeek’s headline 74.8 LiveCodeBench is its thinking mode — a multi-pass reasoning configuration that consumes substantially more inference time per query. Comparing single-pass MiMo to thinking-mode DeepSeek is not entirely fair. But even after correcting for that, the picture is the same: under like-for-like conditions, MiMo-V2.5-Pro is a competent but not cutting-edge code model. Anyone reaching for a trillion-parameter open weight specifically to write Python should reach for Kimi K2 or DeepSeek-V3.1 instead.
Where MiMo Actually Pulls Ahead
The flip side of the coding picture is where MiMo’s design choices visibly pay off. On math, the numbers are striking: 99.6 on GSM8K, 86.2 on MATH, 37.3 on AIME 24/25 averaged. The GSM8K number in particular is at the level where the benchmark stops being meaningful — essentially saturated. AIME is harder and the score is genuinely competitive with much more compute-hungry reasoning-mode models. The MMLU/MMLU-Pro scores (89.4 / 68.5) and BBH (88.4) round out a strong general-knowledge profile.
The other place MiMo wins, and the place its hybrid-attention architecture was clearly built for, is long-context recall. On the GraphWalks benchmark, which asks the model to traverse references inside a very long document, MiMo-V2.5-Pro scores 0.92 on the “Parents” sub-task at 512 K tokens of context and still 0.62 at 1 M tokens. The model card notes that the prior MiMo-V2 collapsed to 0.00 at 1 M tokens; the architectural rework — sliding-window attention plus learnable sink bias plus careful rope-interpolation training — is the difference. There is no other openly downloadable trillion-parameter model with a credibly working 1-million-token context as of April 2026.
So MiMo-V2.5-Pro is best understood as a math-and-long-context specialist that happens to weigh a trillion parameters, rather than as a balanced one-size-fits-all frontier model. It is a tool. It is good at certain tasks.
The Specialization Lesson Hidden in the Numbers
The most interesting thing about putting these four 2025–2026 open models side by side is what their differences imply about the design space. They are within a factor of two of each other in total parameter count and within a factor of one and a half in active parameters. Their architectures all derive from a common ancestor, the Mistral-style sparse mixture transformer with grouped-query attention. The huge gap in their coding numbers, in their math numbers, in their long-context behavior, is therefore not explainable by scale. It is explainable by what each lab decided to do with the training tokens and the RL rounds.
Moonshot Kimi K2 explicitly post-trained for agentic tool use, and the SWE-Bench agentic numbers reflect that. DeepSeek-V3.1 invested in a thinking mode and a careful pre-training mix that disproportionately rewards step-wise reasoning — and its LiveCodeBench score in thinking mode is the consequence. Xiaomi MiMo-V2.5-Pro spent its post-training rounds on math specialization and its architecture rounds on long-context plumbing — and its GraphWalks-at-1M numbers are the consequence.
The lesson, restated for anyone evaluating an open frontier model in the next twelve months: the relevant question is not how big. It is what is it good at, under which inference settings, and with what license. We are entering the part of the open-weight era where the answer to “should I use the bigger one?” is, very often, “no — use the more specialized one.”
Why a Phone Company Has a Trillion-Parameter Model
It is worth pausing on the fact that MiMo comes from Xiaomi at all. Xiaomi is a consumer-electronics company. Its scale and revenue are in handsets, smart-home devices, and increasingly electric vehicles. A foundation model is, on the face of it, an odd thing for a hardware brand to ship under MIT — the work is enormously expensive, the strategic value is unclear, and the license gives the model away to competitors.
The plausible reading is that MiMo is part of a broader Chinese open-source AI play in which Xiaomi has been quietly building since 2024, alongside Alibaba’s Qwen line, Moonshot’s Kimi line, DeepSeek, Tencent’s Hunyuan, Zhipu’s GLM, and Baidu’s ERNIE. For a phone manufacturer with a serious agent and on-device-AI roadmap, having a credible flagship open model means three things: a working showcase for the kind of personalized assistant a phone of 2027 will need; a hiring magnet for the foundation-model talent pool; and an insurance policy against being permanently dependent on someone else’s API. The MIT license suggests Xiaomi is willing to subsidize the public good in exchange for those returns.
Closing Thought
MiMo-V2.5-Pro will not replace Kimi K2 in agentic coding workflows or DeepSeek-V3.1 in deep reasoning ones. That is not what it was built for. What it does mark is the moment at which a fourth major Chinese lab can put a serious open-weight trillion-parameter model on the table without it being remarkable. The category is now plural, and the differentiation among entries is starting to matter more than the headline parameter count. For anyone evaluating these models for production use, the era of treating them as interchangeable is ending; the era of choosing one for a specific job has begun
.
The questions worth asking next are not “is this better than GPT-5?” but “is this better than Kimi K2 for the exact workload I have?” and “what does the licensing let me do that an API does not?” MiMo-V2.5-Pro answers some of those questions affirmatively — for long-context retrieval, for math, for FP8 single-node deployments. For most coding work, the answer is still probably another model. That is a healthy state of affairs for the open ecosystem to be in.
This blog post is based on this research article.
If you liked this blog post, I recommend having a look at our free deep learning resources or my YouTube Channel.
Text and images of this article are licensed under Creative Commons License 4.0 Attribution. Feel free to reuse and share any part of this work. AI was used to support the creation of this article.