
Setting the Bar High: When Science Finally Gets Its Sandbox


In the electrifying, often chaotic world of advanced artificial intelligence, the concept of a “world model” represents one of the most ambitious frontiers. These models aim to give machines the ability to simulate reality—to predict what will happen next when an agent takes an action, allowing them to plan complex behaviors without needing to stumble through the real world repeatedly. We are talking about AI systems that can envision futures, much like we do, making progress in fields from robotics to autonomous decision-making.
However, this dazzling potential has often been hampered by a frustrating scientific reality: the reproducibility crisis. Imagine researchers creating brilliant new engines, but each lab uses a different type of fuel, a different set of gears, and measures speed in a unique way. Comparing “apples to apples” becomes an almost impossible task. A breakthrough in one paper might be impossible to verify because the experimental setup—the data pipeline, the simulator wrapper, the exact evaluation protocol—is locked away in the author’s private code.
It is against this backdrop of methodological fog that the release of `stable-worldmodel` in 2026 arrives, not as a single flash of algorithmic genius, but as something far more foundational: a crucial piece of scientific infrastructure. This GitHub repository is an answer to the reproducibility problem, offering a unified platform designed to level the playing field for world model research.
Building the Common Workshop for Future AI Minds
The innovation here is not a new neural network architecture, but a new system for doing science. `stable-worldmodel` establishes a single, cohesive interface encompassing the entire lifecycle of world model research: from collecting raw data, to training the predictive model, and finally, to evaluating that model using sophisticated planning algorithms like Model-Predictve Control (MPC)
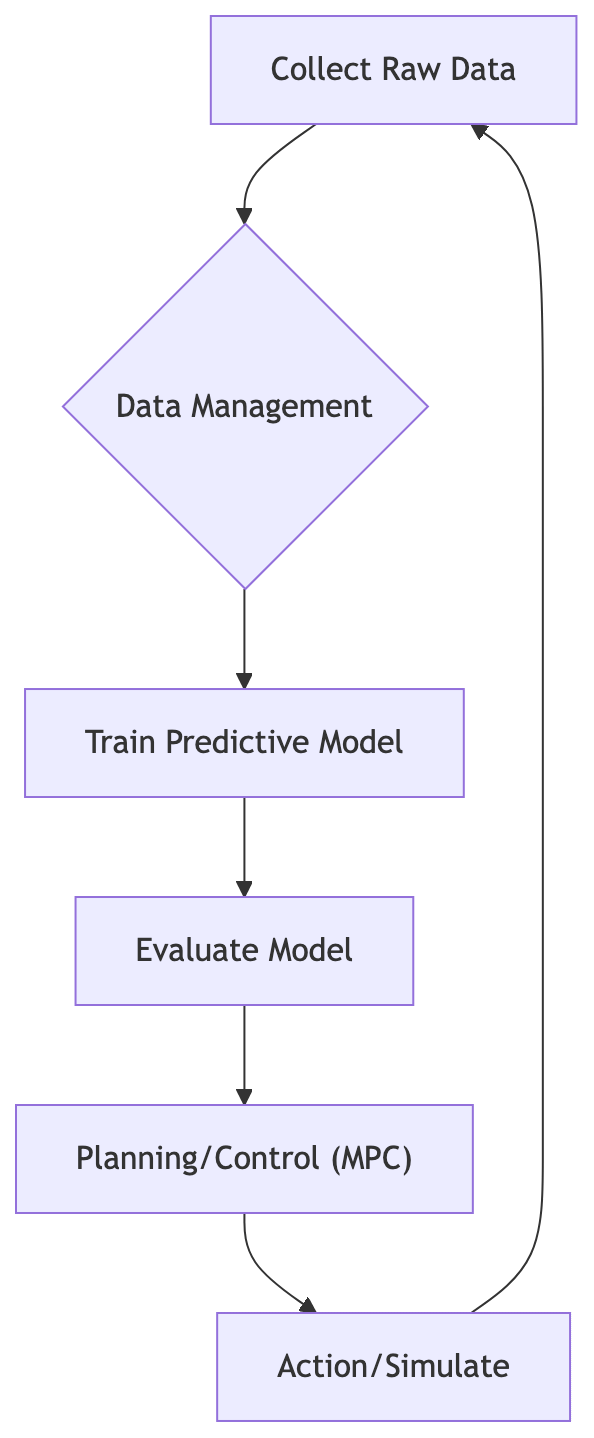
.
The World Model Research Loop. This diagram illustrates the standardized research cycle enabled by the platform, moving from raw data to final planning.
This platform is profoundly significant because it standardizes the entire research loop. Previously, comparing a model built using LeWM against one using DINO-WM often required painstakingly rebuilding the entire data collection and simulation scaffolding for each comparison. `stable-worldmodel` pre-packages this complexity. By shipping reference implementations for common baselines, it allows researchers to strip away the plumbing and focus their intellectual energy purely on the contribution that matters: the model itself and the objective function the wish to achieve

.
Standardization vs. Proprietary Setup. This compares the old, fragmented research style with the standardized, platform-driven workflow.
Deconstructing the Architecture: Data, Training, and Control
To appreciate the depth of this work, one must understand the core components it unifies. At its heart, a world model takes sensory input (like images or sensor readings) and learns to forecast future states. To train such a model, you need massive amounts of high-quality, consistent data.
The platform addresses this data challenge head-on through its sophisticated Data Formats registry. It doesn’t force a single rigid way of storing motion data; instead, it provides an ecosystem of choices tailored to specific needs. For instance, if you need very fast, indexed lookups for training, the platform leverages `lance` format, which organizes data into “episode-contiguous flat rows.” If you need portability, the standard `.h5` file might suffice. But when dealing with long, continuous experiences, the `video` format—packing NumPy arrays with corresponding MP4 video files—offers compact storage. Furthermore, it includes an adapter for `lerobot`, allowing seamless training and evaluation directly against massive, pre-existing datasets hosted on externalhubs
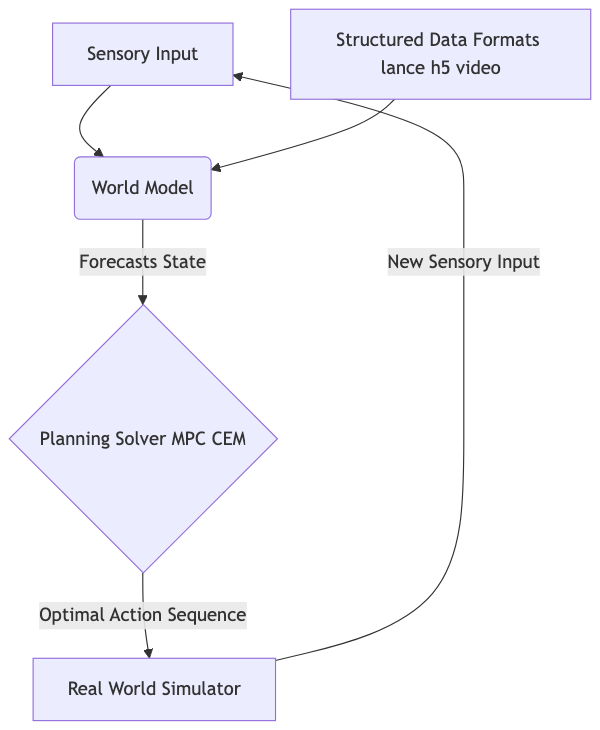
.
Core Components of the World Model Platform. This shows how data formats, training techniques, and planning algorithms interact within the unified system.
Once the data is structured, the platform moves into the training phase, supporting established baselines such as LeWM and DINO-WM, which employ powerful techniques like Joint Embedding Predictive Architectures (JEPA).
Finally, the model must be used to make intelligent decisions. This is where Model-Predictive Control (MPC) comes in. Instead of just reacting to the immediate input, the trained world model allows a planning solver, such as the Cross-Entropy Method (CEM) or Model Predictive Path Integral (MPPI), to look ahead. The solver simulates hundreds or thousands of potential futures based on the world model’s predictions to determine the optimal sequence of actions—a capability that elevates the AI from a sophisticated reactive agent to a true planner.
The Engine Room: Efficiency Benchmarks and Scale
Beyond the conceptual framework, the platform provides tangible, quantifiable benefits. Researchers can trust the performance metrics because they are derived from standardized benchmarking scripts. In a notable demonstration comparing storage formats on the challenging PushT dataset, the efficiency gains are clear. For instance, using LanceDB versus HDF5 locally, the data throughput dramatically increases. The repository benchmarks show that LanceDB can achieve up to 4814.8 samples per second in its non-cached local setting, compared to HDF5 hitting a peak near 1474.0 samples per second when cached locally. Furthermore, in terms of storage footprint, LanceDB requires only about 13.31 GB locally, significantly less than the 43.12 GB required by HDF5 for the same dataset. These concrete numbers confirm that the platform is built not just for correctness, but for efficiency at scale.
The scope of this endeavor is vast. The environments themselves draw from established benchmarks in reinforcement learning and classical control, including DeepMind Control Suite, Gymnasium classic control, OGBench, and Craftax. A key feature enabling generalized research is the concept of “factors of variation” (FoV) in these environments. Many worlds come pre-equipped with parameters for lighting, texture, or dynamics that can be independently altered, allowing researchers to immediately test how robust their world model is to real-world distribution shifts without any extra manual setup.
A Collective Effort Towards Scientific Maturity
What makes this repository so impressive is the collaborative spirit evidenced by the sheer breadth of integration. While the repository itself is managed under the `galilai-group` umbrella, the complexity of such a system—integrating multiple cutting-edge algorithms, managing diverse data I/O, and standardizing a high-level interface—requires deep, coordinated engineering and research insight. This was achieved by a dedicated team of contributors, including Lucas Maes, Quentin Le Lidec, Luiz Facury, Nassim Massaudi, Ayush Chaurasia, Francesco Capuano, Richard Gao, Taj Gillin, Dan Haramati, Damien Scieur, Yann LeCun, and Randall Balestriero.
The Horizon of Impact
The release of `stable-worldmodel` signals a maturation point for the entire world model field. It moves the discussion from “Can we build a world model?” to “How can we rigorously compare different world models?”
For the next generation of researchers, this platform is less of a tool and more of a shared global laboratory. Instead of spending months fighting serialization errors or attempting to replicate a specific evaluation setup, scientists can immediately plug their novel predictive algorithms into the standardized flow. Imagine an academic student today being able to take a concept proven in a highly specialized, proprietary lab environment and, within days, test it rigorously against LeWM and DINO-WM on the same standardized suite of 20+ diverse environments, like PushT or FetchPickAndPlace.
This platform promises to accelerate the convergence of theoretical AI models with practical, verifiable performance. It helps ensure that when we claim a new world model is “better,” we mean it across a broad, agreed-upon measure of competence, opening the door for world models to transition from academic curiosities into reliable components of truly intelligent, real-world agents.
The full research, including the details of this platform, is documented in the accompanying paper, referenced as arXiv:2605.21800, and the entire code infrastructure is made available for the community to explore and build upon.
This blog post is based on this research article.
If you liked this blog post, I recommend having a look at our free deep learning resources or my YouTube Channel.
Text and images of this article are licensed under Creative Commons License 4.0 Attribution. Feel free to reuse and share any part of this work. AI was used to support the creation of this article.